TDT Application
Trade Data Tool
International Merchandise Trade Statistics (IMTS) is a crucial data set on the overall economic statistics framework characterized by reliance on administrative data sources such as customs declarations, aircraft/ship registers, records of commodity boards, or relevant ministries. The raw data from these sources are collected daily having a large volume of information. For IMTS compilers, data tools are required to process and verify the raw data, and for these, two distinct tools made their way into the IMTS community: Eurotrace from Eurostat and PC Trade from Statistics New Zealand. In 2020, UNSD started a process to assess, reflect, and develop a plan for the future of Trade Data Tools. Namely by assessing the existing trade data tools, developing a feasibility study for enhanced trade data tools, and preparing a proof of concept on trade data tools for the UN Global Platform. The project has been undertaken to develop a Trade Data Tools (TDT) prototype in collaboration with Eurostat.
Activities in 2020-2021
In 2020, the United Nations Statistics Division (UNSD) conducted a global assessment survey to evaluate existing trade compilation tools, including Eurotrace and PC Trade. This survey focused on identifying functional requirements and potential improvements. Following the survey, a virtual focus group meeting was held at the beginning of 2021, featuring participants from countries that utilize Eurotrace and PC Trade. Both initiatives resulted in detailed specification documents that guided the development of new tools.
In 2021, most activities centered on the development of trade data tools, which were managed by IT contractors under the supervision of UNSD and Eurostat project managers. The development process focused on the following modules:
- Architecture and infrastructure design
- User experience/interface design and development
- Development of core modules, including metadata, data management, file handling, a rule engine, data pipeline, error engine, and gold data creation
Additionally, in 2021, preliminary user guidelines and manuals were drafted, and several tests were conducted.
Activities in 2022-2023
In 2022, the initial plan was to stabilize and expand the modules while conducting a pilot project for experimentation and testing. However, due to changes in technology selection, the focus shifted to modifying and stabilizing the core modules, particularly to develop the minimum viable product (MVP) for testing (details on status are provided below). The involvement of two experts with extensive experience in the implementation of Eurotrace allowed the team to address the requirements identified in the TDT prototype developed in 2021.
In March 2023, the MVP and a draft of the user manual were released for the next stage of implementation, which includes awareness activities and pilot implementation throughout the remainder of 2023. So far, TDT has been presented or will be presented at the following events:
- East African Community (EAC) in-person workshop in March 2023
- African Union Commission (AUC) in-person Specialized Technical Group in April 2023
- Southern African Customs Union (SACU) in-person workshop in May 2023
- Association of Southeast Asian Nations (ASEAN) virtual Expert Group meeting in September 2023
Activities in 2024
In early 2024, the team undertook a mission to implement a Proof of Concept in Eswatini utilizing the actual data and validation rules. At this point, the working prototype, various user guides for installation and configuration, and some training materials are ready. One of the mission outcomes is the need to have TDT on-premises in addition to TDT local and TDT cloud, considering the needs of countries. In the rest of 2024, the technical team will continue improving the TDT in various aspects, including deployment for on-premises and UI improvement.
Eurotace vs. TDT
In terms of features, Eurotrace and TDT are very similar – both aim to assist compilers in compiling trade data. However, there are some differences in terminologies and ways to define the structure and rules. Furthermore, to assist the understanding of TDT deployment, the table below shows the non-functional features between Eurotrace and TDT
Table 1. Comparison of non-functional features between Eurotrace and TDT
| Eurotrace | TDT | |
| Ability to directly interact with datasets in the database (access controlled) | No | Yes |
| Ability to scale horizontally to process multiple datasets at a time (multiple servers serving in parallel) | No | Yes |
| Ability to deploy on multiple platforms (cloud, client-server and local deployment) | No (only local deployment with remote database) | Yes |
| Ability to add new components on the go (without deploying) | No | Yes |
| Ability to scale services independently (for example, Scale only pipeline services as it does most of the heavy lifting) | No | Yes |
| Is technology/programming language agnostic? | No | Yes (designed as a set of independent microservices) |
| Licenses required? | Yes/No (needed if SQL server or Oracle databases are used) | No (all the tools used are open source, including the database Mariadb) |
| Data storage (to persist the uploaded files and other reference files as required) | No | Yes (through file service, which uses Minio behind the scenes) |
| Support for multiple data analytical languages such as SQL/Python/R | Only SQL (templated versions) | Yes |
| Possibility to integrate with user's own data source for cross-analysis | No | Yes (through Zeppelin notebooks with connectors) |
Note: All other missing features of Eurotrace, such as SDMX support, data editing support, etc., will be implemented in due course.
TDT Data Architectures
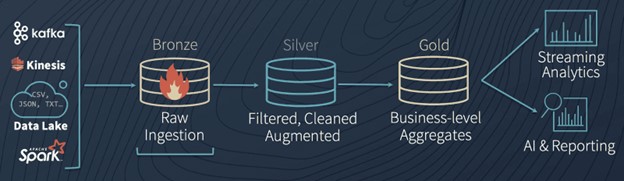
Bronze, silver, and gold datasets:
TDT (Trade data tools) manages data at different levels, which are referred to as "Bronze," "Silver," and "Gold." These terms are derived from the data lake concept, primarily used by the Delta Lake project of Apache Spark. The Bronze level represents raw data in its original form, and any data fed into the system will initially land in the Bronze zone. The Silver level represents curated and disaggregated data resulting from applying necessary rules defined in the system to the Bronze data. The Silver level also serves as a single source of truth. The Gold level represents more curated and aggregated data and can be compared to data cubes in data warehousing. Users can create as many Gold datasets as they need from Silver data and have as many Bronze (source) datasets as required. However, only one Silver dataset is possible. The diagram below illustrates these levels.
Apache Zeppelin
It is an open-source web-based notebook that provides an interactive environment for data ingestion, exploration, visualization, and collaboration. A Zeppelin notebook is an interface that allows users to execute code and view the results of that code, including visualizations and textual output. Zeppelin notebooks consist of paragraphs similar to cells in a Jupyter notebook. Zeppelin notebooks are designed for admins and SQL experts who access the database directly from this tool, allowing them to test their rules and analyze their data in the TDT.
Pipelines
TDT manages rules in the form of pipelines. A pipeline contains many stages, each containing a ruleset (or Zeppelin notebook). Ruleset contains a set of SQL queries that are applied to the bronze data to produce silver data or applied to silver data to produce gold data. These rules are defined inside the Zeppelin notebook. Pipelines consist of multiple stages, each consisting of one Zeppelin notebook. Each notebook contains multiple rulesets, which represent individual SQL queries.

Contact
Please reach out to comtrade@un.org if you would like to learn more or be part of the pilot implementation.